Tracking AI Visibility: The Prompt Monitoring Playbook
You can't optimize what you can't measure. A practical framework for tracking how often your brand appears in AI answers across models.
Rank tracking told you where you sat on a Google SERP. Prompt monitoring tells you whether you exist inside an AI-generated answer. It is the foundational measurement layer of AI Visibility Optimization — and unlike SERP rank, there is no Search Console pre-built for it.
Why prompt monitoring is the new rank tracking
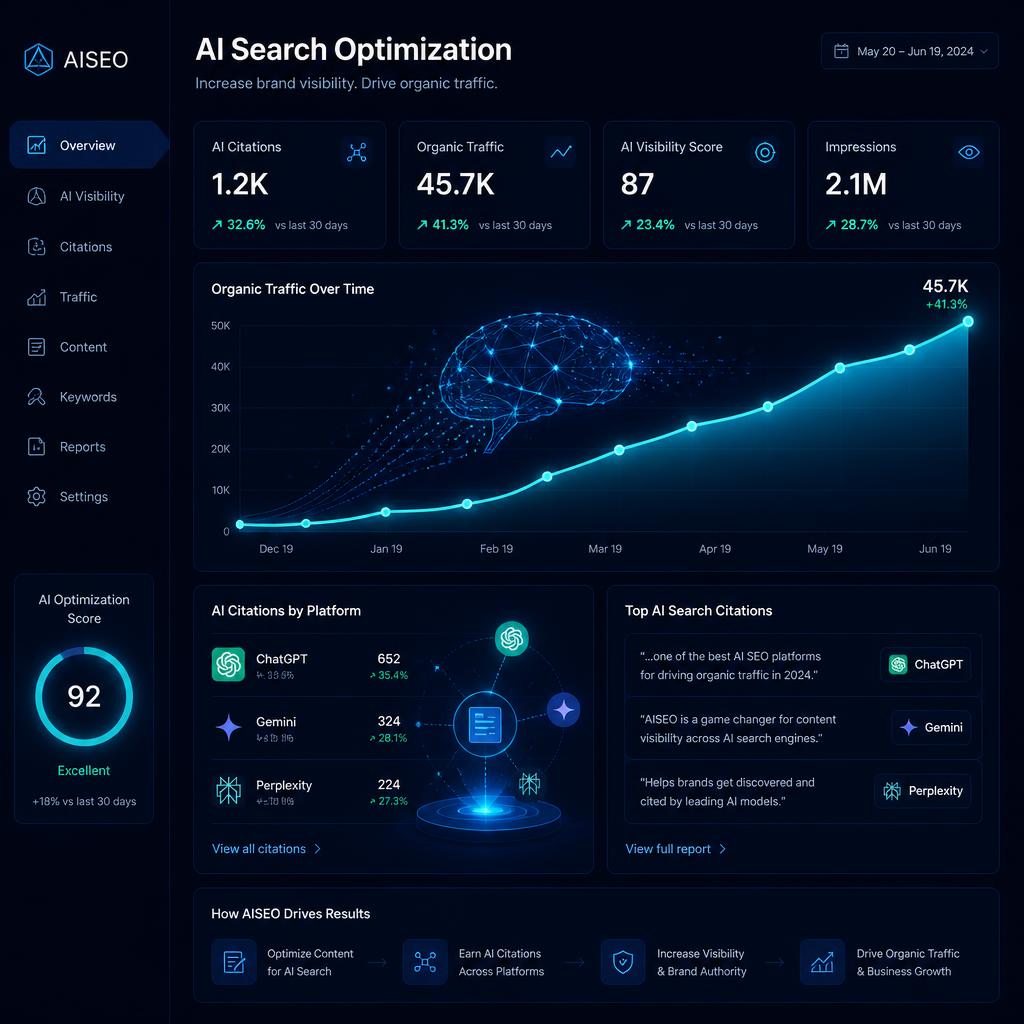
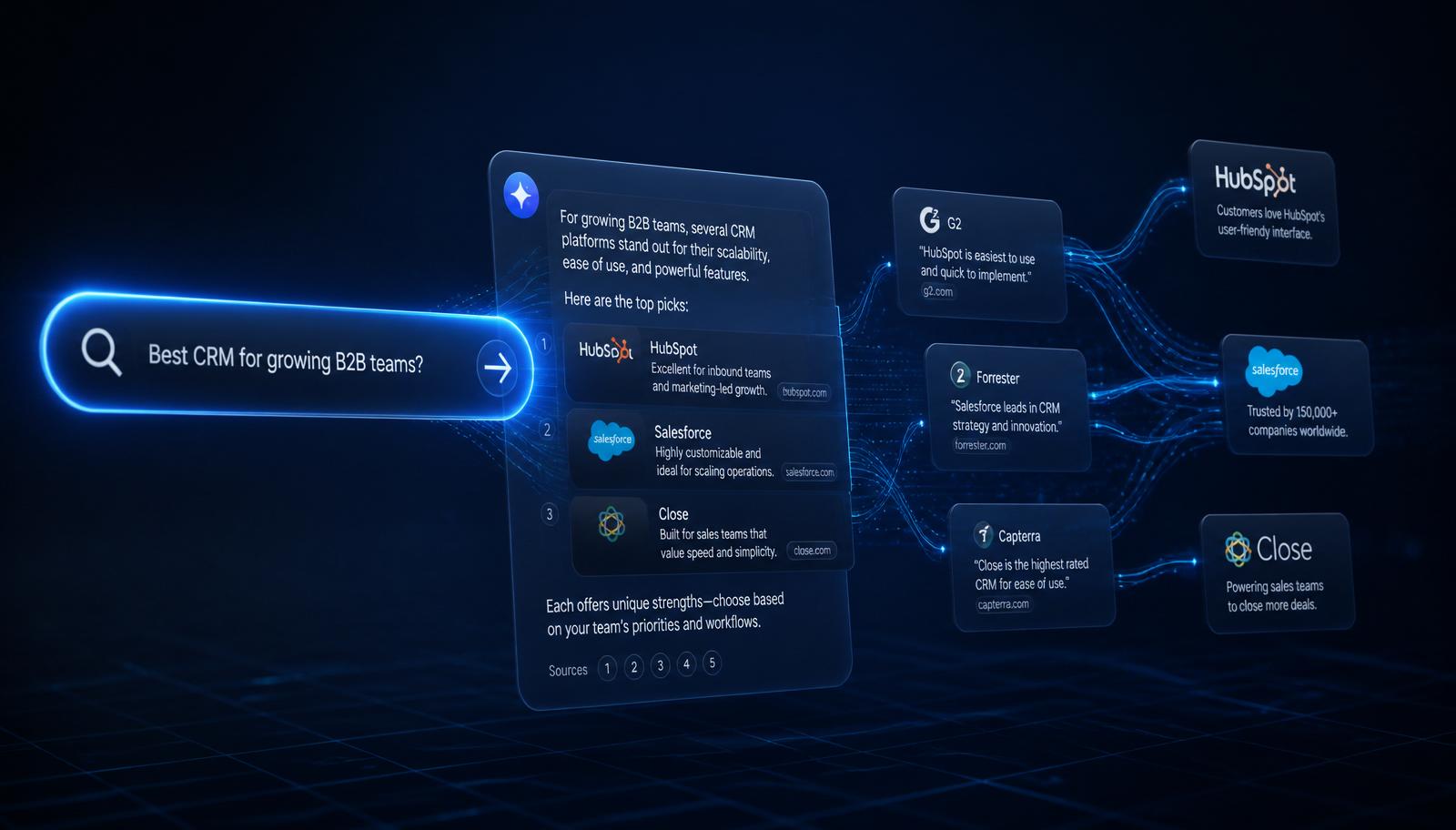
When buyers ask ChatGPT, Gemini, Claude, or Perplexity to recommend a vendor, the answer they see is the only result that exists. There is no scroll, no page two, no 'related searches.' Either your brand is cited or it is not. A 0–100% citation rate on a buyer prompt is the AVO equivalent of a #1 organic ranking, and it changes weekly as models update.
Step 1 — Build a prompt set that mirrors buyer intent
Start with 100–500 prompts that mirror how customers in your category actually phrase questions to AI. Cover five intent buckets: category recommendations ('best {category} for {audience}'), comparisons ('X vs Y vs Z'), problem-first ('how do I solve {pain}'), brand-specific ('is {brand} good for {use case}'), and geographic ('best {category} in {city/region}'). Pull real phrasing from sales call transcripts, support tickets, Reddit threads, and Search Console queries.
Step 2 — Run the set across all four major models, weekly
Run the same prompt set against ChatGPT, Gemini, Claude, and Perplexity on a weekly cadence. Use API access where available and headless browser sessions where not. Capture the raw answer text, the cited sources, and the timestamp. Save everything — week-over-week deltas are the signal.
Step 3 — Score four metrics per prompt
(1) Citation rate: did your brand appear, yes/no. (2) Position: first mention, body, or footnote. (3) Sentiment: positive, neutral, or negative framing. (4) Competitive set: which other brands appeared in the same answer. Aggregate to a category-level Share of AI Voice — your citation rate divided by total competitor citation rate.
Step 4 — Close the loop into your content and entity workstreams
Every uncited prompt is a content gap, an entity gap, or a citation gap. Route each gap to the right team: missing on a comparison prompt → publish or update a comparison page with Product and FAQPage schema. Missing on a geographic prompt → fix LocalBusiness schema and earn local press. Missing on a category prompt → strengthen your Wikidata/Wikipedia entity and earn citations on the publication that won the slot instead.
Tooling: what to use in 2026
Purpose-built AVO platforms (Profound, Peec, Otterly, Atomik Digital's internal tracker) automate the runs and the diffing. DIY teams can stand up a workable v1 with a spreadsheet, the OpenAI/Anthropic/Google APIs, Perplexity's API, and a weekly cron. The cost of measurement is low; the cost of not measuring is months of work pointed at the wrong gaps.
Reporting cadence
Weekly internal deltas for the AVO team. Monthly Share of AI Voice trendline for leadership. Quarterly competitive deep dive comparing your brand against the top three citation winners in your category. The brands that win AVO treat prompt monitoring the same way SaaS teams treat product analytics — a continuous feedback loop, not a one-time audit.
Want to see where your brand ranks?
Run a free AI Visibility Audit across the major models.
Run Free AI Audit