How ChatGPT Decides Which Brands to Cite
Inside the retrieval and grounding pipeline that determines whether your company shows up in an AI answer — and how to engineer for it.

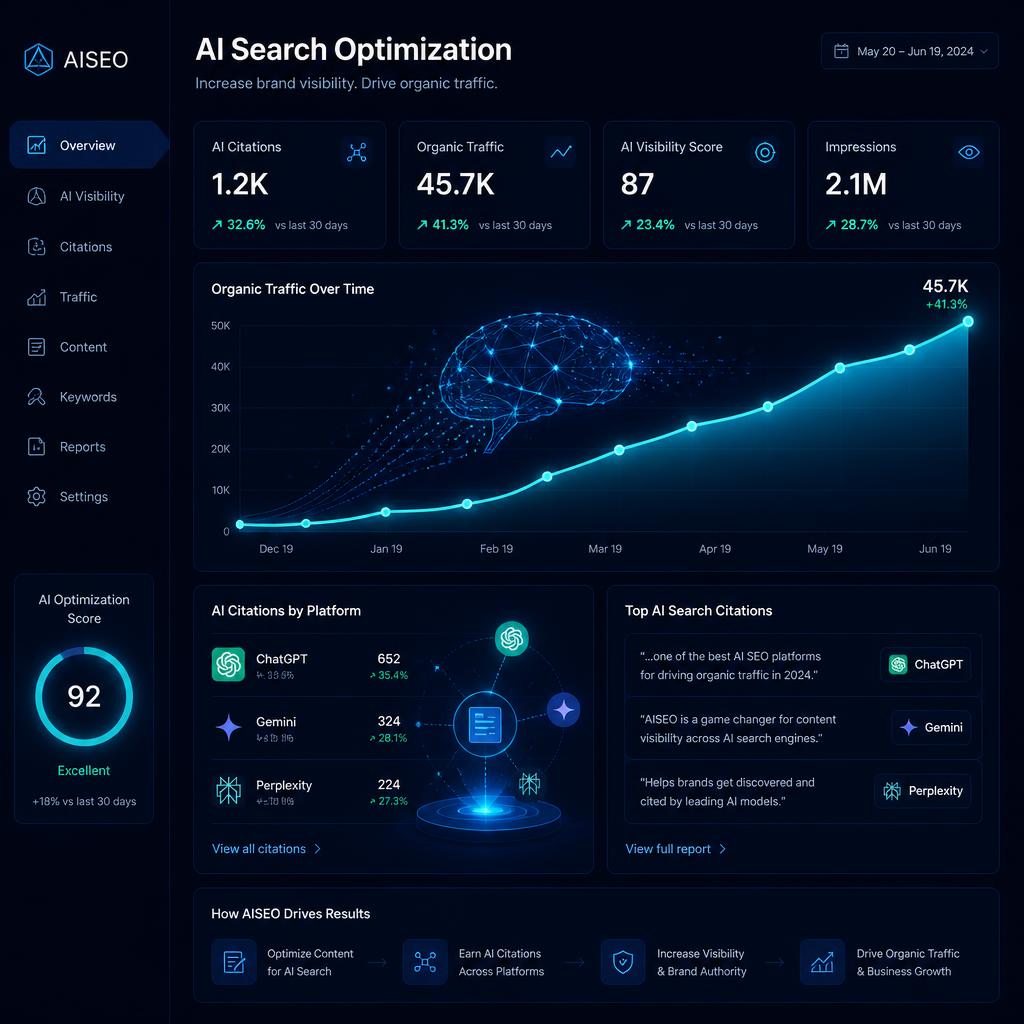
Citations in ChatGPT, Perplexity, Google's AI Overviews, and Gemini are not random. They are the output of a retrieval-augmented generation (RAG) pipeline that scores candidate documents on freshness, authority, structured signals, and entity match. Understanding that pipeline is the difference between being cited weekly and being invisible.
Step 1 — Query understanding and entity resolution
Before retrieval runs, the model decomposes the prompt into intents and entities. 'Best CRM for solar installers in Arizona' is parsed as intent (recommendation), category (CRM), audience (solar installers), and geography (Arizona). If your brand cannot be resolved as a CRM entity tied to that audience and region, you are eliminated before retrieval begins.
Step 2 — Hybrid retrieval across multiple indexes
Modern LLM products run hybrid search — dense vector similarity plus lexical BM25 — across multiple indexes: the open web (via Bing for ChatGPT and Copilot, Google for Gemini, proprietary crawls for Perplexity and Claude), licensed publisher datasets, and structured knowledge graphs. Each index returns candidate passages.
Step 3 — Reranking on authority and freshness
Candidate passages are reranked using cross-encoder models that weigh source trust (domain authority, editorial reputation), recency (publication and last-modified dates), and structural quality (clean HTML, schema markup, semantic headings). A six-month-old blog post on a low-authority site is dropped in favor of a fresh, schema-rich page from a trusted publisher — even if the keyword match is weaker.
Step 4 — Grounding and synthesis
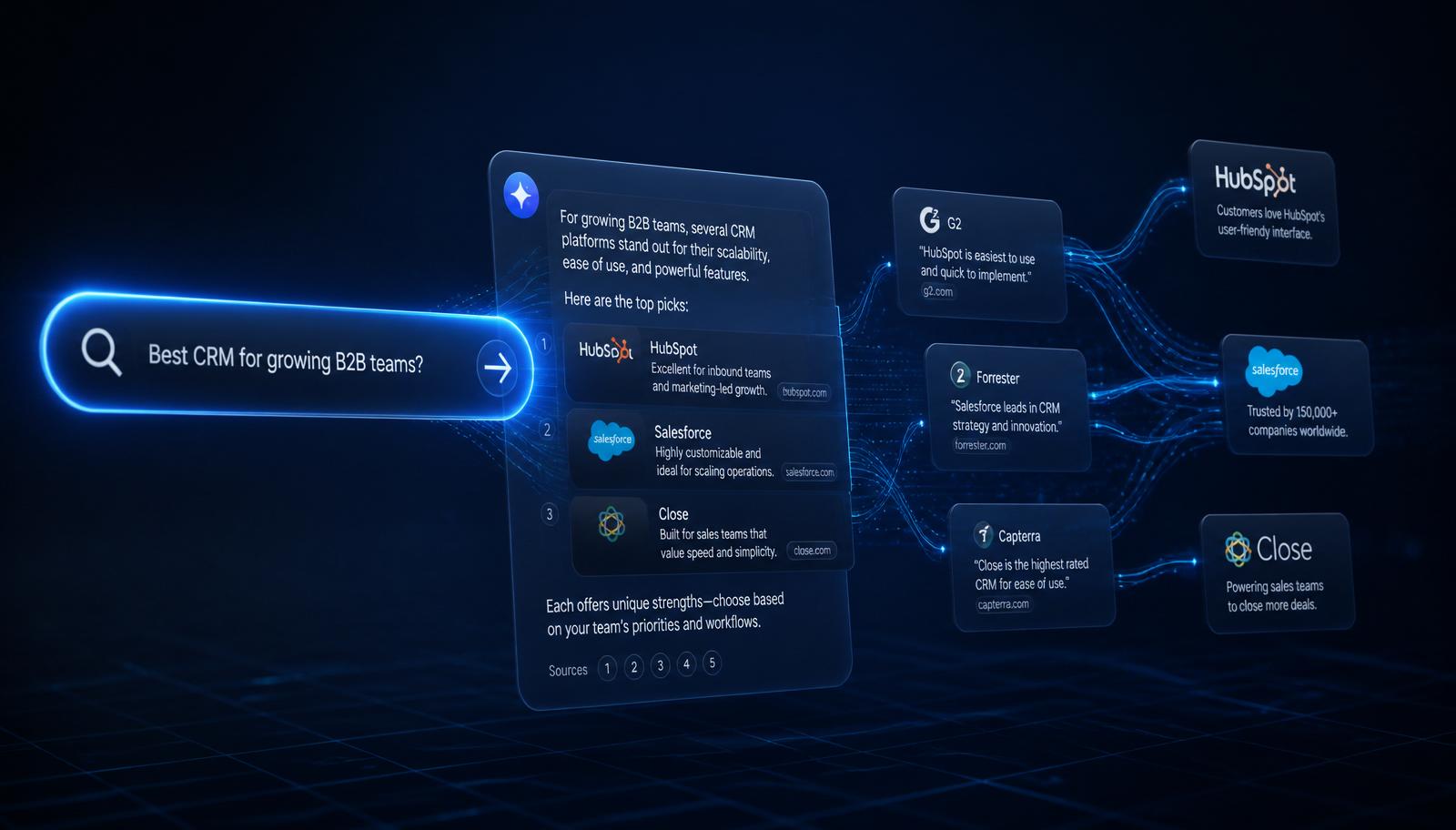
The reranked passages are passed to the LLM as grounding context with explicit instructions to cite. The model composes an answer and emits citations to the passages it actually used. Brands mentioned inside those grounded passages become the cited sources users see and click.
What our citation logs reveal
Across hundreds of tracked prompts at Atomik Digital, the brands cited most often share five traits: (1) one canonical brand name used consistently across the web, (2) dense Organization and Product schema with sameAs links to Wikipedia, Wikidata, LinkedIn, and Crunchbase, (3) third-party citations on publications that ChatGPT and Perplexity sample heavily (Reuters, TechCrunch, Forbes, G2, industry trades), (4) a Wikipedia or Wikidata entry that disambiguates the brand from similar names, and (5) fresh, comprehensive category pages updated in the last 90 days.
Differences between ChatGPT, Gemini, Claude, and Perplexity
ChatGPT (with Bing grounding) over-indexes on Reddit, Wikipedia, and large publishers. Gemini leans heavily on Google's Knowledge Graph and YouTube transcripts. Claude favors long-form, well-structured editorial sources. Perplexity is the most citation-explicit and tends to surface a wider long tail. Optimizing for citation means engineering presence across all four — strategies that win on Perplexity often translate, but they are not identical.
Engineering your site for citation
Treat your site as a knowledge base, not a brochure. Publish definitive resources on the questions your buyers actually ask AI. Disambiguate your brand with consistent NAP, Organization schema, and sameAs links. Earn citations on the publications LLMs trust. Re-audit monthly — every model update and index refresh reshuffles the citation leaderboard.
Measuring lift
Pick 100–500 buyer prompts. Run them weekly against ChatGPT, Gemini, Claude, and Perplexity. Track citation rate, sentiment, position, and which competitors appear alongside you. Lift is measured in citation-rate delta over time — the only metric that matters in AVO.
Want to see where your brand ranks?
Run a free AI Visibility Audit across the major models.
Run Free AI Audit